Цитата:
Поэтому допилить для данной задачи именно Оберон-07 представляется разумным
По ходу дела возникают ещё соображения, если вдруг гипотетически что-то допиливать. Кроме проблематики "лимитов" для циклов есть ещё одна существенная штуковина. Если не использовать break/exit-ы и соблюдать инварианты и пр., то те же циклы вынуждают частенько прибегать к "грязным" приёмам в виде "побочных эффектов" в предикатах (условиях).
Вспоминается показательная дискуссия:
"Выход из цикла или смерть Кощея", где требуется "эффективно" без лишних затрат (якобы важно) найти иглу (и ещё схожая задача):


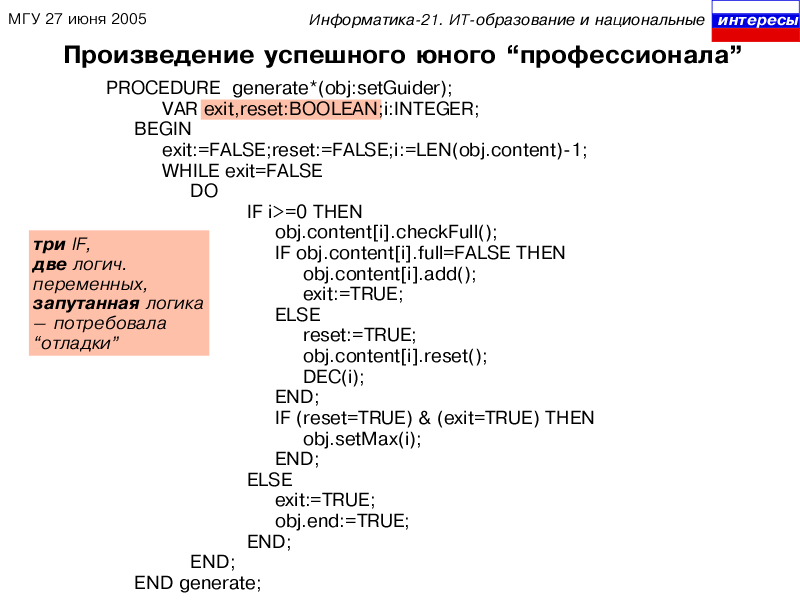
Для понятности и "под доказательство" типовой стиль решения аля:
http://oberspace.dyndns.org/index.php/topic,425.msg13278.html#msg13278Код:
PROCEDURE Store (obj: ANYPTR; VAR ptr: ANYPTR): BOOLEAN;
BEGIN
ptr := obj;
RETURN obj # NIL
END Store;
i := 0;
WHILE (i < сундуки.length) &
~( Store(ЗАЯЦ(сундуки[i]), заяц)) & Store(УТКА(заяц(Заяц)), утка)) &
Store(ЯЙЦО(утка(Утка)), яйцо)) & Store(ИГЛА(яйцо(Яйцо)), игла)) )
DO
INC(i)
END
, где в условии while вместо ожидаемого анализа результатов работы выполняются непосредственно содержательные прикладные действия. Причём упорядоченность действий зависит от примененного порядка логических операций (и от порядка аргументов) -- семантически эти операции (как и порядок аргументов) для этого не предназначены, в технологическом языке (в данном языке программирования) последовательность определяется через ";" плюс "защитные" выражения (if-ы) да условия повторения действий.
Для С-подобных языков решение может быть таким (комментарий к коду был в "исходнике"):
http://oberspace.dyndns.org/index.php/topic,425.msg13047.html#msg13047Код:
// На Си можно избежать дублирования кода пользуясь тем фактом,
// что оператор присваивания возвращает значение:
i = 0;
while ((i < колВоСундуков) && (
!(заяц = ЗАЯЦ(сундуки[i]))
|| !(утка = УТКА(заяц)))
|| !(яйцо = ЯЙЦО(утка))
|| !(игла = ИГЛА(яйцо))
)) ++i;
Этот случай более "продвинутый" в том смысле, что в нём хоть заметны результаты прикладной работы -- присваивание переменных (вместо визуально скрытого изменения аргументов при вызове процедур в предыдущем варианте решения задачи). Правда в С это присваивание ещё нужно заметить. В ряде современных С-производных языков в таких случаях есть "прогресс" и могут требовать введения новых переменных по месту через модную попсовую конструкцию аля "let" вида:
!(let заяц = ЗАЯЦ(сундуки[i]))
Ну, а ключевое в той дискуссии было след. решение от её инициатора:
http://oberspace.dyndns.org/index.php/topic,425.msg13272.html#msg13272

, где с помощью нового оператора "andwile" условие while-цикла как бы временно "разрывается" (с проблемками), но с соблюдением "каноничности" инвариантов с постусловием и пр.:
http://oberspace.dyndns.org/index.php/topic,425.msg13861.html#msg13861Вообще-то, проблематика "грязных" предикатов навязывается не только циклами. Поэтому решение выше если и приемлемое, но лишь частично, в смысле прочие аспекты не решает. К примеру -- там же вариант задачи "близко к идеальному" (заметка к коду была в "исходнике"):
http://oberspace.dyndns.org/index.php/topic,425.msg13083.html#msg13083Код:
WHILE list.HasMoreElements() AND смерть = NIL DO
сундук := list.GetNext();
IF сундук.UnpackTo( заяц ) AND
заяц .UnpackTo( утка ) AND
утка .UnpackTo( яйцо ) AND
яйцо .UnpackTo( игла ) AND
игла .UnpackTo( смерт ) THEN
Log.String("капец Кащею");
END;
END;
+1. Близко к идеальному. Смотришь и всё сразу понятно.
Про "UnpackTo" и прочее:
http://oberspace.dyndns.org/index.php/topic,425.msg13078.html#msg13078В варианте выше оператор "if" по сути-то пустой, указан лишь как необходимое синтаксическое средство для выражения порядка действий с "защитными" условиями в виде логической операции (композиции) -- ибо так проще, быстрее, удобнее и понятнее, вроде как. В некоторых современных языках ещё больше упрощают чтоб "не париться", как в Julia, где техника построения кода, такого как ниже, декларируется на уровне "report-а о языке" (с соответствующей поддержкой синтаксиса и семантики):
https://docs.julialang.org/en/stable/manual/control-flow/#Short-Circuit-Evaluation-1Код:
function fact(n::Int)
n >= 0 || error("n must be non-negative")
n == 0 && return 1
n * fact(n-1)
end
Кстати, можно обратить свое внимание: сходу ли понятна логика действий, если встречается не только сплошные "and"? (ну..., данный пример ещё не самый показательный).
Примечательно то, что ведь такой код для математической аудитории, на которую прежде всего ориентируется Julia, по сути-то есть высшая степень издевательства над математической формой коммутативных операций.
На фоне всех "издевательств" выше, вообще-то, как-то уже и не прилично утверждать, что в IT "контуперность" лишь крепчает, если, к примеру, обратить внимание на Rust, где внедряются "рекурсивные лямбды" -- в соответствие с концепцией продвинутого "expression-oriented функционально-императивного" языка и loop-ы должны быть с возможностью являться "expression по месту", в которых break-и могут возвращать данные (а может быть это есть попытка "спасти" предикаты?):
https://github.com/rust-lang/rfcs/blob/master/text/1624-loop-break-value.mdПопытки снять "издевательство" над предикатами были и на этом форуме, к примеру -- конструкция "AND THEN":
https://forum.oberoncore.ru/viewtopic.php?f=27&t=3175&hilit=andifТамошние идеи получили развитие в виде концептуальных конструкций "прогресса" и его циклической вариации (плюс прочее условные и циклические выражения) в проекте PureBuilder:
https://sites.google.com/site/purebuilder/Однако, видимо, сложные и разнообразные конструкции не приживаются, если можно ведь "по-простому" на базе имеющихся логических средств.
В функциональных языках ситуация чуть иная. В тех же ML-подобных вариациях кроме популярности рекурсивных методов (со своими достоинствами и недостатками) есть и те же императивные итерационные циклы. Причём в тех краях имеется "внедрение" переменных в виде оператора "let ... in" (или математического "где": "... where ..." ) как на примере ниже:
https://realworldocaml.org/v1/en/html/imperative-programming-1.html#for-and-while-loops-1Код:
let rev_inplace ar =
let i = ref 0 in
let j = ref (Array.length ar - 1) in
(* terminate when the upper and lower indices meet *)
while !i < !j do
(* swap the two elements *)
let tmp = ar.(!i) in
ar.(!i) <- ar.(!j);
ar.(!j) <- tmp;
(* bump the indices *)
incr i;
decr j
done
, где как раз i и j "внедряются" в while-цикл (на всякий случай: оператор "!" есть извлечение значения из "ссылки"). В данном случае let...in скомпонованы в цепочку, что явно выражает последовательность. В целом let (или where) содержат композицию "паттернов" (шаблонов для паттерн-матчинга) -- пусть это по-простому будут "уравнения".
Однако, как видно из примера, в целом семантика "let" предполагает вычисление соответствующего значения по требованию и дальнейшее его использование, в т.ч. и многократное. Т.е. в данном случае i и j вычисляются один раз (создаются "ссылки") и далее лишь используются.
В некоторых ML-вариациях вместо let...in может быть форма оператора "whith ...", как к примеру:
"with ... do ... done"
, что семантически имеет в большей степени окрас "подмешивания". А в "топорном" Lustre и его вариантах семантика вычислений "уравнений" уже чуть иная, там блоки "многоразового" вычисления ("бесконечно" работающие автоматы).
Без вводных объяснений попробую в порядке бреда изобразить потенциальное "внедрение" уравнений для цикла while по мотивам Lustre, но для Паскале-подобного языка. В Lustre-like языках как в Паскалях есть строгое требование определять переменные в начале (фактически аля те же var-секции перед телом процедуры), однако когда удобно возможны и локальные переменные, но в рамках своих подблоков, и также в начале задаются (нечто вроде ML-вских "local ... in ..."). Пусть блок уравнений задаётся в виде:
local <список переменных> with <уравнения> <выражение>
, где секция local с переменными не обязательная, <уравнения> "внедряются" для <выражение>, которое как-то идентифицируется (пока неважно как именно, пусть как "begin ... end" или любое иное допустимое, пока без подробностей).
Ниже псевдо-код по мотивам "поиска иглы":
Код:
...
var
игла: pointer;
i: integer;
begin
...
игла := nil;
i := 0;
local
заяц, утка, яйцо: pointer
with
rec заяц := ЗАЯЦ(сундуки[i])
and утка := if заяц <> nil then УТКА(заяц) else nil
and яйцо := if утка <> nil then ЯЙЦО(утка) else nil
and игла := if яйцо <> nil then ИГЛА(яйцо) else nil
while (i <> len(сундуки)) && (игла = nil) do
i = i + 1;
end;
...
end;
, где оператор "and" как в ML -- отделяет условно (или потенциально) рекурсивные объявления (уравнения в данном случае, в ML возможны и иные виды деклараций), "rec" -- необязательное "начало" рекурсивных объявлений, указано просто для выделения and-ов в один столбец.
Семантику оператора with подразумеваем как некие Lustre-блоки, выражающие такты автомата. Поскольку уравнения в примере привязаны к циклу, то при каждой итерации происходит вычисление уравнений (а точнее -- изменение переменных). В данном случае как только первично обращаются к переменной "игла" при каждой итерации (в рамках привязанного <выражение>) происходит предварительное её вычисление (обновление), что приводит к редукции, т.е. к "раскручиванию" всех связанных уравнений (как обычно в функциональных языках или во всяких Modelica и т.п.). Переменная "игла" является внешней по отношению к оператору with.
В примере в уравнениях используются if-ы для "защиты". В функциональных языках и в их подражателях часто для таких случаев используют алгебраические типы аля "Option[a] = Some(a) | None" и соответствующий "паттерн-матчинг". Однако, в Lustre есть стандартное понятие "наличие данных", как бы некий типовой виртуальный Option, используемый по умолчанию и отчасти скрыто (что снижает необходимость явно использовать соответствующие операции проверок). Уравнение вычисляется (исполняется действие) только тогда, если доступны все(!) необходимые данные. Если при "раскручивании" такта автомата выясняется, что данные на входе действия не могут быть получены в полной мере, то действие не совершается, и его результат считается отсутствующим (в тех краях это есть понимание наличия/отсутствия сигналов и реакции на них).
По мотивам выше приведенного, попробуем оптимизировать (упростить) пример. Вместо алгебраического типа (соответственно без потребности хранить в памяти вспомогательные тэги типов или значений, но enum-ы и т.п. не отменяются) будем использовать обычный integer, но укажем компилятору условие для типа, что бы он понимал "наличие данных" -- директива "present", и значение "по умолчанию" -- нет данных (в Esterel/Lustre-краях так интерпретируется состояние "проводов" в цифровых схемах -- есть/нет сигнал):
Код:
...
var
игла: integer default (0) present (> 0);
i: integer;
begin
...
игла := 0;
i := 0;
local
заяц, утка, яйцо: integer default (0) present (> 0)
with
rec заяц := ЗАЯЦ(сундуки[i])
and утка := УТКА(заяц)
and яйцо := ЯЙЦО(утка)
and игла := ИГЛА(яйцо)
while (i <> len(сундуки)) && (not игла) do
i = i + 1;
end;
if игла then
...
end;
end;
Функция (или процедура) как "УТКА(заяц: integer): integer" может быть разработана в сторонке со "строгими" обычными integer-ами, но при конкретном её использовании её результат может быть преобразован к "null-able" типу (как в примере). Процедура может задавать в своём объявлении на входе (и выходе) "null-able" тип (соответственно внутри процедуры требуются соответствующий анализ или чего там нужно). У компилятора есть возможность отслеживать потребность в проверках (и "нагибать" разработчика при случаях), или же организовывать runtime-проверки по аналогии отслеживания доступа по nil-значению. В случае "null-able" типа его интерпретация как boolean выглядит вполне понятной.
Недостатки также имеются. Прежде всего, не всегда система уравнений достаточна наглядна и может потребовать явного указания возникающих связей. В таких случаях помогают аля dataflow-схемы в каком-либо виде. Или же в редакторе "отсортировать" уравнения по зависимостям. Но поскольку речь о "подмешивании" уравнений, то требуется некий "баланс", подмешивать в меру.
В Оберонах оператор with используется для другого, но это не важно, поскольку дальнейшее расширение концепции выше для Оберона, скорее всего, является именно что бредом. Во-первых, не соответствует стереотипам "максимального sample", как минимум возникает некое дублирование функционала, т.е. прикручиваются альтернативные средства для базовых. К тому же требуются if-ы как expression (и аналог "match...with..." из ML), а то и "инфиксные защиты" для удобства аля:
яйцо := ЯЙЦО(утка) when заяц = подходящий
Во-вторых -- согласно иным распространённым принципам -- слишком много "закулисной магии", якобы нет явного предписания действий. Это в каком-нибудь ML-выкрутасе "инъекции уравнений" -- нормальны и естественны (или же инъекции "императивщины" в системы уравнений, в зависимости от стиля кода).
А жаль. Ведь язык соблюдает некоторые математические устои. В самом деле, "обновление" или присваивание переменной вместо "x := x + 1" такая форма как "x = x + 1" также есть "издевательство" над "сравнением", если взглянуть на само содержимое операции. Множество в виде "{...}" и др.
Но, всё-таки, неоднозначно то, что издевательство над предикатами в виде "побочных эффектов" является простой и надёжной формой выражения действий.